多线程网络爬虫
给定一个链接 startUrl 和一个接口 HtmlParser ,请你实现一个网络爬虫,以实现爬取同 startUrl 拥有相同 域名标签 的全部链接。该爬虫得到的全部链接可以 任何顺序 返回结果。
你的网络爬虫应当按照如下模式工作:
- 自链接
startUrl 开始爬取
- 调用
HtmlParser.getUrls(url) 来获得链接url页面中的全部链接
- 同一个链接最多只爬取一次
- 只输出 域名 与
startUrl 相同 的链接集合

如上所示的一个链接,其域名为 example.org。简单起见,你可以假设所有的链接都采用 http协议 并没有指定 端口。例如,链接 http://leetcode.com/problems 和 http://leetcode.com/contest 是同一个域名下的,而链接http://example.org/test 和 http://example.com/abc 是不在同一域名下的。
HtmlParser 接口定义如下:
1
2
3
4
| interface HtmlParser {
public List<String> getUrls(String url);
}
|
下面是两个实例,用以解释该问题的设计功能,对于自定义测试,你可以使用三个变量 urls, edges 和 startUrl。注意在代码实现中,你只可以访问 startUrl ,而 urls 和 edges 不可以在你的代码中被直接访问。
示例 1:
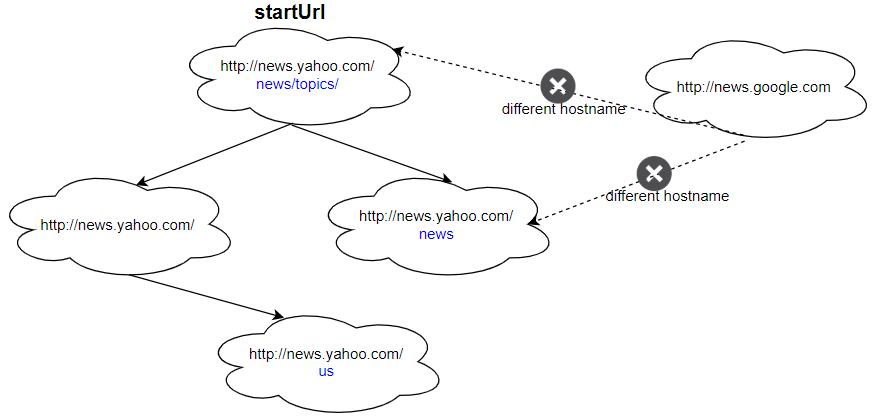
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| 输入:
urls = [
"http://news.yahoo.com",
"http://news.yahoo.com/news",
"http://news.yahoo.com/news/topics/",
"http://news.google.com",
"http://news.yahoo.com/us"
]
edges = [[2,0],[2,1],[3,2],[3,1],[0,4]]
startUrl = "http://news.yahoo.com/news/topics/"
输出:[
"http://news.yahoo.com",
"http://news.yahoo.com/news",
"http://news.yahoo.com/news/topics/",
"http://news.yahoo.com/us"
]
|
示例 2:
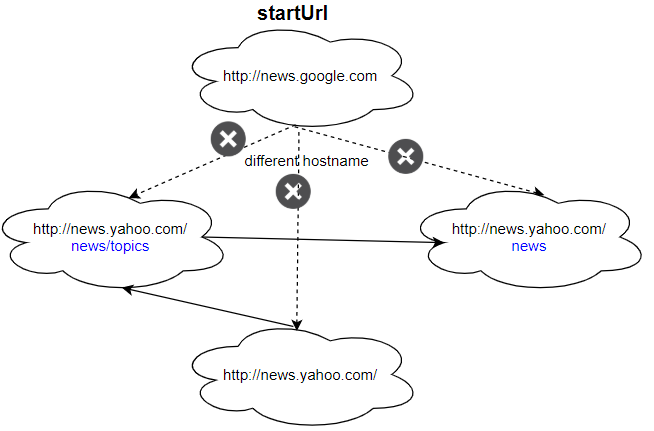
1
2
3
4
5
6
7
8
9
10
11
| 输入:
urls = [
"http://news.yahoo.com",
"http://news.yahoo.com/news",
"http://news.yahoo.com/news/topics/",
"http://news.google.com"
]
edges = [[0,2],[2,1],[3,2],[3,1],[3,0]]
startUrl = "http://news.google.com"
输入:["http://news.google.com"]
解释:startUrl 链接到所有其他不共享相同主机名的页面。
|
核心思想: 在进行bfs时需要使用多线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| BlockingDeque<String> deque = new LinkedBlockingDeque<>();
HtmlParser htmlParser;
ConcurrentHashMap<String, Boolean> set = new ConcurrentHashMap<>();
public List<String> crawl(String startUrl, HtmlParser htmlParser) {
this.htmlParser = htmlParser;
set.put(startUrl, true);
deque.addLast(startUrl);
Thread thread = new Thread(this::dsth);
thread.start();
try {
thread.join();
} catch (Exception ignore) {
}
return new ArrayList<>(set.keySet());
}
void dsth() {
List<Thread> threads = new ArrayList<>();
String s = deque.pollFirst();
for (var ss : htmlParser.getUrls(s)) {
if (set.containsKey(ss)) continue;
if (getHost(s).equals(getHost(ss))) {
set.put(ss, true);
deque.addLast(ss);
Thread thread = new Thread(this::dsth);
threads.add(thread);
thread.start();
}
}
for (var thread : threads) {
try {
thread.join();
} catch (InterruptedException ignore) {
}
}
}
String getHost(String url) {
String substring = url.substring(7);
int i = substring.indexOf('/');
if (i != -1) {
return substring.substring(0, i);
} else return substring;
}
|
-
为什么需要join?
join是让当前正在运行的线程先阻塞,让给指定线程,我们必须保证主线程在最后执行。
-
为什么需先把thread先存起来然后依次调用join?而不是每次start()完后就join?
每次start()完后直接join的话会导致性能降低,每次都得等先执行完。